





























































按照正常流程编程的话,比如按N切分,硬件所执行的流程为:搬入数据->计算数据->搬出数据->搬入数据->计算数据->....->搬出数据。而数据的搬运和数据的计算分别由GDMA和BDC控制,因此,当执行GDMA时,BDC为闲置状态,执行BDC时,GDMA为闲置状态。
因此,一个简单的想法是利用乒乓缓冲,达到同时使用GDMA和BDC的目的。
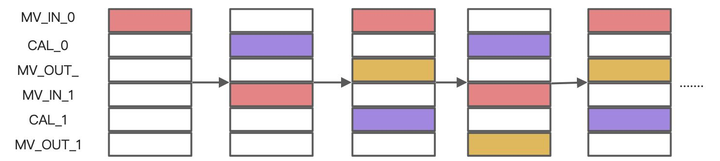
以上图为例:
(1) 搬入第一块的输入。
(2)计算第一块,同时搬入第二块的输入。
(3)搬出第一块的输出,搬入第一块的输入,同时计算第二块。
(4)搬出第二块的输出,搬入第二块的输入,计算第一块,之后重复(3)(4),直到运行结束,可以看到,除了开始和结束的搬运,之后所有时间内,GDMA和BDC都是同时工作的。
伪代码以 output=input+1.0 为例,通过奇偶性来控制访问的地址:
local_addr_t input_addr[2], output_addr[2];
for(int i=0; i<blocks+2; i++)
{
okk_parallel_start(); //标志开始并行
if(i<blocks)
S2L(input_addr[i%2], param->input_addr + i*input_skip_bytes); // 搬运数据
if(i>0 && i<blocks+1; i++)
add_one(output_addr[(i-1)%2], input[(i-1)%2]); // 计算上次搬运的数据
if(i>1)
L2S(param->output_addr + (i-2)*output_skip_bytes, output_addr[(i-2)%2]); //搬出上次计算好的数据
okk_parallel_end();
}
包含在okk_parallel_start()和okk_parallel_end()中的操作会被并行执行。更详细的代码见算丰文档。