





























































typedef struct {
int left_rows, left_cols, right_cols; //左矩阵行,左矩阵列,右矩阵列
unsigned long long output_addr; //输出矩阵地址
unsigned long long left_addr; //左矩阵地址
unsigned long long right_addr; //右矩阵地址
} __attribute__((packed)) param_t;
param_t params[] = {
{.left_rows = 2, .left_cols = 100352, .right_cols = 2048 }, // 0
{.left_rows = 2, .left_cols = 1280, .right_cols = 1000 }, // 1
{.left_rows = 2, .left_cols = 25088, .right_cols = 4096 }, // 2
{.left_rows = 4, .left_cols = 1024, .right_cols = 25088}, // 3
{.left_rows = 32, .left_cols = 2048, .right_cols = 36 }, // 4
{.left_rows = 64, .left_cols = 9216, .right_cols = 4096 }, // 5
{.left_rows = 79, .left_cols = 256, .right_cols = 4090 }, // 6
{.left_rows = 200, .left_cols = 4096, .right_cols = 324 }, // 7
{.left_rows = 256, .left_cols = 768, .right_cols = 3072 }, // 8
{.left_rows = 256, .left_cols = 3072, .right_cols = 768 }, // 9
{.left_rows = 300, .left_cols = 2048, .right_cols = 80 }, // 10
{.left_rows = 1024, .left_cols = 1024, .right_cols = 1024 }, // 11
{.left_rows = 2048, .left_cols = 4, .right_cols = 1024 }, // 12
{.left_rows = 12544, .left_cols = 2, .right_cols = 1024 }, // 13
{.left_rows = 100352, .left_cols = 1024, .right_cols = 1 }, // 14
};
关于矩阵在local memory中的存储方式,与tensor的存储方式稍有不同,详见算丰文档。在编程时需要注意的是合理分配每个TPU上的数据大小,来尽可能多的利用TPU的算力。
如果左矩阵、右矩阵以及结果矩阵能够同时存放到local memory中,那么所作的事情就比较清晰了:搬入左右矩阵->计算结果->搬出结果矩阵。伪代码如下:
local_addr_t left_addr, right_addr, output_addr;
param_t* param;
matrix_S2L(left_addr, param->left_addr);
matrix_S2L(local_right_addr, param->lright_addr);
okk_bdc_matmul(output_addr, left_addr, right_addr);
matrix_L2S(param->output_addr, output_addr);
所给测试用例中的大部分用例都无法直接存入local memory中,因此,需要利用分块矩阵乘法,对矩阵进行切分。
这里提供三种切分的思路。
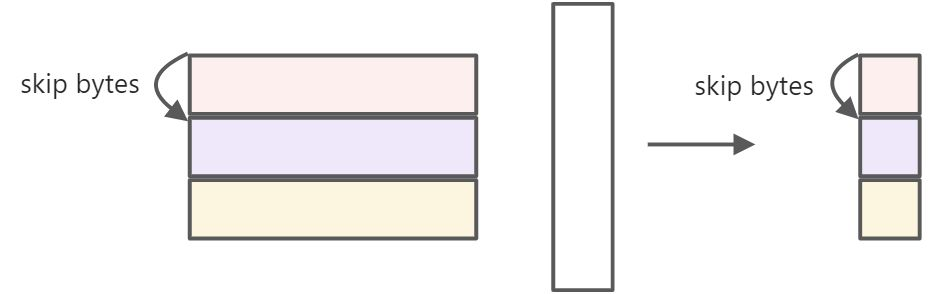
如图,当左矩阵较大,而右矩阵较小时,可以考虑按左矩阵的行来进行切分,例如测试用例中的用例14。这样的情况下,可以固定右矩阵,循环搬入左矩阵的待计算部分以及搬出部分输出矩阵。
local_addr_t left_addr, right_addr, output_addr;
param_t* param;
matrix_S2L(right_addr, param->right_addr);
for(int i;i<blocks;i++)
{
matrix_S2L(left_addr, param->left_addr + left_skip_bytes);
okk_bdc_matmul(output_addr, left_addr, right_addr);
matrix_L2S(param->output_addr + output_skip_bytes, output_addr);
}
其中需要注意左矩阵的最后一块,因为左矩阵的行数并不能总是被块数整除,因此最后一个块的大小和之前块的大小会有不同。
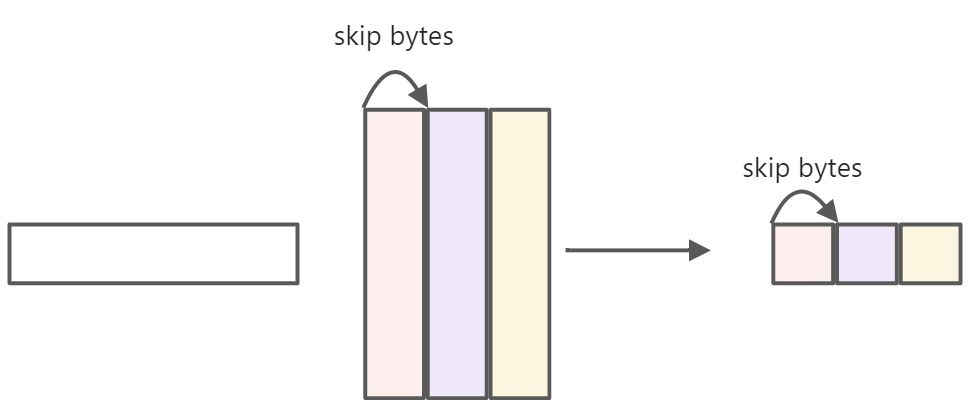
同样的,当右矩阵较大,而左矩阵较小时,可以考虑按右矩阵的列进行切分,例如测试用例中的用例4。我们可以固定左矩阵不动,循环搬入右矩阵进行计算,并搬出输出矩阵。
local_addr_t left_addr, right_addr, output_addr;
param_t* param;
matrix_S2L(left_addr, param->left_addr);
for(int i;i<blocks;i++)
{
matrix_S2L(right_addr, param->right_addr + right_skip_bytes, right_cols_in_memory); //right_cols_in_memory控制搬运时内存每行有多少列,这样在搬运一部分的时候会跳过该行而不是只跳过已搬运的元素
okk_bdc_matmul(output_addr, left_addr, right_addr);
matrix_L2S(param->output_addr + output_skip_bytes, output_addr, right_cols_in_memory);
}
这里需要注意的是,矩阵在内存中是按行存储,因此在按左矩阵切分时,可以简单搬运数行,但是在按右矩阵列进行切分时,会有不连续的问题,因此需要在搬入矩阵时,设置在内存中矩阵的列数,以此来仅选取当前块的数据。
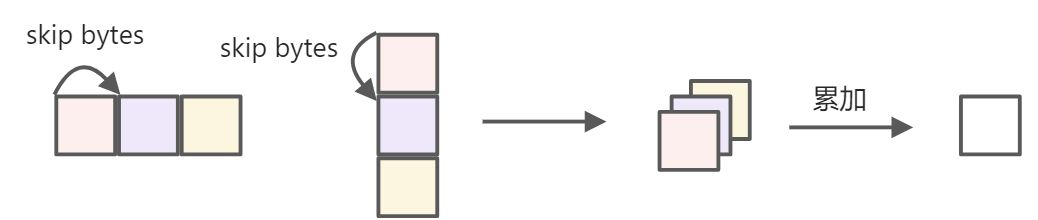
此外,还有一种情况,如测试用例中的用例0,由于左矩阵的列以及右矩阵的行都比较大,导致单一矩阵都无法存入TPU,因此需要对左矩阵的列进行切分。对不同部分的运算结果进行累加,并搬运最终的输出矩阵。
local_addr_t left_addr, right_addr, output_addr;
param_t* param;
okk_bdc_set_C(output_addr, 0.0); //将输出矩阵置0,累加初始化
for(int i=0; i<blocks; i++)
{
matrix_S2L(left_addr, param->left_addr + left_skip_bytes);
matrix_S2L(right_addr, param->right_addr + right_skip_bytes);
okk_bdc_matmul(output_addr, left_addr, right_addr, result_add=True); //通过result_add控制是否将结果累加到输出地址上
}
matrix_L2S(para->output_addr, output_addr);
matmul部分没有比较好的特例优化方式,可能主要是控制col_per_NPU这样的参数,来达到尽可能多的利用算力的目的。
通过以上的几张方法,基本能够通过所提供的测试用例。如果遇到更大的矩阵,可以考虑通过行列都切分的方式进行计算。